我们选购电脑时,CPU处理器的配置会有缓存大小,它是CPU性能的重要指标。 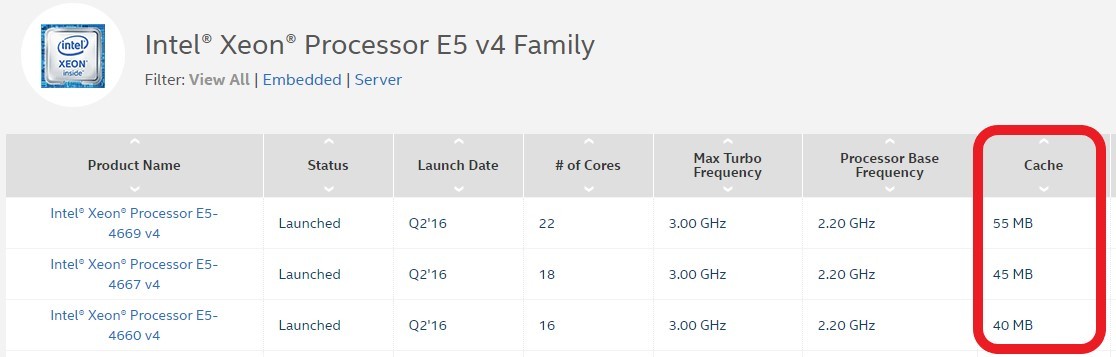
为什么呢?因为CPU计算速度与访问主存速度非常不匹配!
先来看计算速度。单颗CPU计算速度目前在2GHz-4GHz之间,以2.5GHz计即每秒钟计算25亿次,每个时钟周期耗时1/2.5GHz==0.4纳秒。当前所有的计算机都遵循冯诺依曼结构,所以执行任何指令(例如加法操作)的流程必然遵循下图: 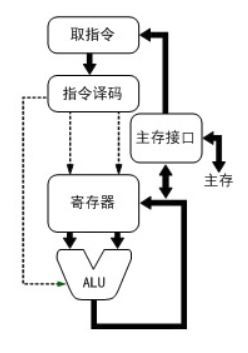
所以,做一次加法的指令是由多个时钟周期组成的(如取指令和数字、放入寄存器、执行ALU、将结果写回主存),做ALU执行指令仅需要1个时钟周期,而取指令或者取数据、回写结果数据就需要与主存打交道了。CPU访问内存(主存)的速度非常慢,访问一次常常需要上百纳秒以上,这与计算指令有千倍的差距!怎样解决访问主存慢导致的CPU计算能力的浪费呢?加入CPU缓存!
CPU上增加缓存后,由于CPU缓存离CPU核心更近,所以访问速度比主存快得多!如果我们访问内存时,先把数据读取到CPU缓存再计算,而下次读取到该数据时直接使用缓存(若未被淘汰掉),这在时间和空间上都会降低CPU计算能力的浪费!在时间上,有些数据访问频率高(热点),多次访问之间都未被淘汰出缓存;在空间上,缓存可以同时加载相邻的数据、代码,这样函数、循环的执行都在使用缓存中的数据。
CPU缓存是分为多级的,原因是热点数据太大了!最快的缓存一定离CPU核心最近,因为体积小所以容量也最小,不能满足以MB计算的热点数据。最终发展出了三级缓存,分别称为L1、L2、L3级缓存。这三级缓存的访问速度各不相同,但都远大于访问主存的速度(访问时间更小),如下图所示: 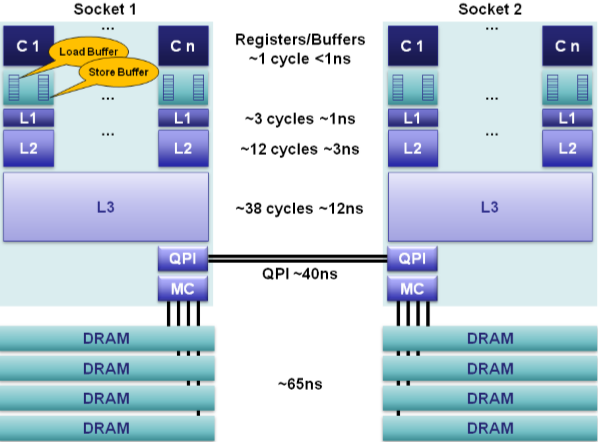 可见,L1和L2的缓存访问速度非常快,只有不到3ns,L3稍慢一些,但都远小于访问主存的速度。当然,CPU缓存的大小也远小于主存的大小,如本文最开始的那张图,现在的CPU缓存往往只有几十MB。如果大家点击具体的CPU细看缓存,可以看到intel只标明了smart cache,如下图所示(intel e5-2620 v4):
可见,L1和L2的缓存访问速度非常快,只有不到3ns,L3稍慢一些,但都远小于访问主存的速度。当然,CPU缓存的大小也远小于主存的大小,如本文最开始的那张图,现在的CPU缓存往往只有几十MB。如果大家点击具体的CPU细看缓存,可以看到intel只标明了smart cache,如下图所示(intel e5-2620 v4): 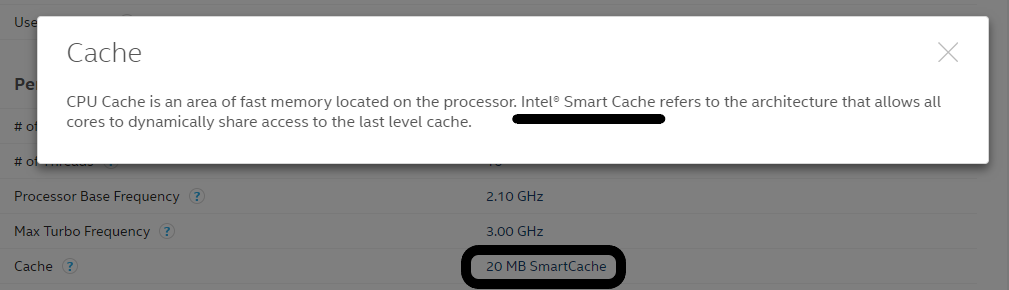 这个smart cache其实就是L3缓存,现在的CPU都是多核心的,而smart cache就是智能的被多CPU核心共用的意思。那么L1、L2缓存大小为什么不标出来呢?其实没有必要,因为通常L1就是32KB,而L2是256KB,在linux上我们可以直接看到:
这个smart cache其实就是L3缓存,现在的CPU都是多核心的,而smart cache就是智能的被多CPU核心共用的意思。那么L1、L2缓存大小为什么不标出来呢?其实没有必要,因为通常L1就是32KB,而L2是256KB,在linux上我们可以直接看到:
1 | model name: Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10GHz |
这里,index0和index1分别代表L1缓存中的指令缓存和数据缓存,index2是L2缓存,index3就是L3缓存。也可能一个缓存由多个CPU共享,仍然以E5-2620 v4这个8核16线程的CPU为例:
1 | [root@zldfwq103 ~]# cat /sys/devices/system/cpu/cpu0/cache/index1/shared_cpu_list |
笔者的服务器有两颗e5,所以表现为32颗逻辑CPU。由于intel的超线程技术,所以两颗逻辑CPU对应一颗物理CPU。简单插一下何谓超线程技术:由于访问主存的速度太慢,所以intel想了一个主意,就是当CPU在等待从主存中调入数据或者指令时,同时做另一个任务,这样一颗CPU就表现为两颗逻辑CPU,如下图所示: 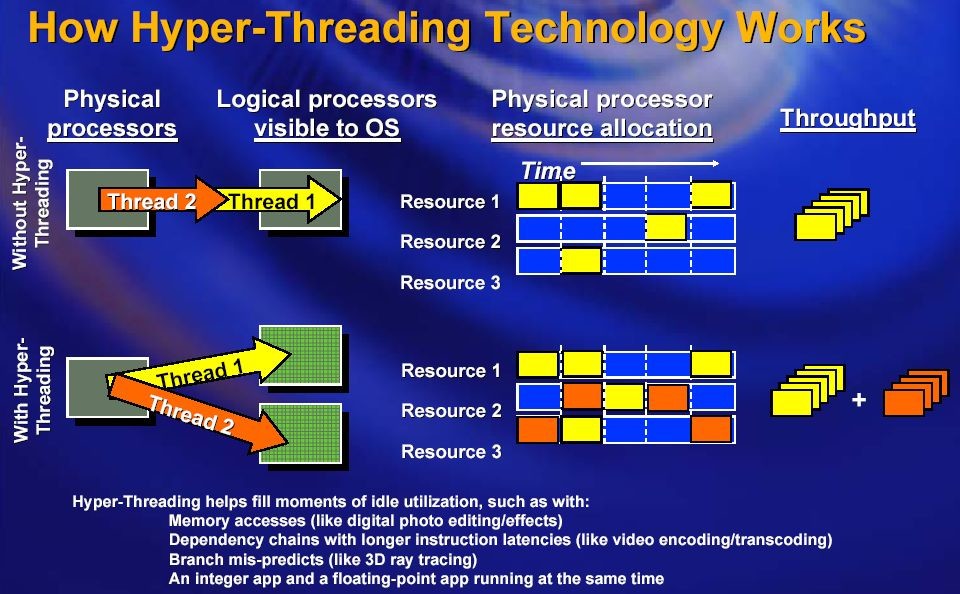 从
从shared_cpu_list可见,20MB的L3缓存被16颗逻辑CPU(8颗物理CPU)共享,而L2和L1都是由一颗物理CPU独占的。 CPU缓存与主存交换数据每次大小是固定的,我们称其为cpu cache line,在64位系统下通常是64字节,在linux下可以这么获取该值:
1 | [root@zldfwq103 ~]# cat /sys/devices/system/cpu/cpu1/cache/index3/coherency_line_size |
在C语言程序里,可以通过sysconf (_SC_LEVEL1_DCACHE_LINESIZE)获取,例如在nginx 1.13.8版本后是这么获取的:
1 | + |
为什么需要cpu cache line这个数值呢?因为它对提高性能是有用的!比如nginx中存储http header的hash表。假设我们的cache size是64字节,而一个hash bucket是48字节。假如某一个bucket的起始地址是1F7D030,那么它占用的内存就从1F7D030到1F7D05F,而cache size的特性导致只会从64的整数倍地址访问,于是需要访问两次:1F7D000和1F7D040。而如果我们能使得hash bucket大小是cache size的整数倍,那么就不会出现访问一个hash bucket需要两次操作主存的情况。比如,若原本bucket size是32,则设为64;原本为96,则设为128,即向上对齐。nginx有一个向上对齐函数就是做这个事的:
1 |
|
上面这个ngx_align算法来源于一个数学特性:对于正整数2^n(n>1)来说,存在这样的特性,如果整数X是2^n的整数倍,则X的二进制形式的低n位为0, 如果X不是2^n的整数倍,则X与(~(2^n-1))进行与运算可以得到一个与X相近的是2^n整数倍的正整数。对于上对齐,则需要先加上2^n-1,再进行上述运算。 事实上,如果hash bucket没有对齐cache line,那么出现访问一个bucket要调用两次载入主存数据的操作可能性非常大!比如上面的例子中hash bucket size是48,即使第一个bucket没有跨cache line,第2个bucket一定会跨从而导致两次主存访问! 当CPU获取数据时,cpu缓存由于已经存有数据,那么核心可以直接使用缓存,不用再去访问内存了,这一过程我们称为cache hit命中!反之,称为cache miss。可见,如果我们的程序在循环或者热点代码中,能够控制数据规模,使之长期落在CPU缓存中,那么性能就可以提升!怎么判断CPU缓存命中率现在是多少呢?在linux下可以通过perf命令轻松实现(centos下通过yum install perf安装),如下所示:
1 | [root@zldfwq103 test]# perf stat -B -e cache-references,cache-misses ./test5 64 |
当然,perf支持很多事件,包括进程上下文切换等,上面的cache-references,cache-misses两个事件分别代表缓存命中和未命中。perf支持的事件很多,如下表所示:
1 | branch-instructions OR branches [Hardware event] |
使用perf来定位程序性能的瓶颈是个有效的办法! 下一篇我们来讨论怎样写出能利用好CPU缓存的代码。