当下性能测试已成为确保软件质量的关键环节。其中,wrk作为一款轻量级、高性能的HTTP基准测试工具,以其简洁的命令行界面和出色的性能著称。wrk通过-c参数能够模拟高并发的网络请求,帮助我们评估服务器在极端负载下的表现。如果你打算做C10K数万并发连接这个量级的测试,wrk是合适的(相比ab/jmeter等工具),然而,如果你想尝试进行数百万级别的高并发测试时,官方wrk就无能为力了。
首先,wrk不支持自定义源IP地址,这在需要模拟来自不同客户端的请求时尤为不便,做并发测试时TCP连接数也上不去(此时你在curl命令中验证会看到类似Cannot assign request address的错误)。其次,wrk在每个连接上预分配的内存相对较大,这在单机上尝试建立大量连接时,会导致内存资源迅速耗尽,wrk进程会因为OOM被内核杀掉(如果wrk进程突然消失,你通常可以在/var/log/messages中看到形如Out of memory的日志)。这些限制对于需要评估高性能服务的开发者来说,无疑是一个不小的障碍。
在接下来的内容中,我将探讨如何通过修改wrk源码解决上述问题,以期帮助读者更好地利用wrk进行极限并发测试。
wrk与高并发测试挑战
在软件工程实践中,性能测试是确保应用性能达标的核心环节。比如容量测试会评估系统的最大处理能力;压力测试会评估系统在高负载下的行为;瓶颈测试会识别高负载情况下可能影响性能的系统限制因素。本文主要关注容量测试中的并发连接/会话测试,即如何达到预定的并发连接数,并不会考虑同一时间的吞吐量、每秒新建连接数等指标。
wrk的核心优势在于其轻量级和高性能,它通过C语言+epoll这种异步事件驱动架构,能够在短时间内生成大量的HTTP请求,测试目标服务器的响应时间和吞吐量。wrk的设计哲学是简单至上,它提供了一个简洁的命令行界面,用户可以通过-c参数指定并发线程数、-d指定请求持续时间、-t指定使用线程数等,快速启动测试,并在SSL测试中自动忽略不合法证书(相当于curl命令加入了-k参数)。
做C10M并发测试时,有一个必然的限制条件:测试目标通常集中在一个业务上,这就意味着业务监听的VIP(虚拟IP地址)和端口是固定的。在TCP连接的五元组(包括源IP、源端口、目的IP、目的端口、协议类型,如下图所示)中,协议类型、目的IP和端口由于业务需求已经确定,这限制了我们只能在源IP和源端口上寻求建立多连接的可能性。UDP会话也面临同样的问题。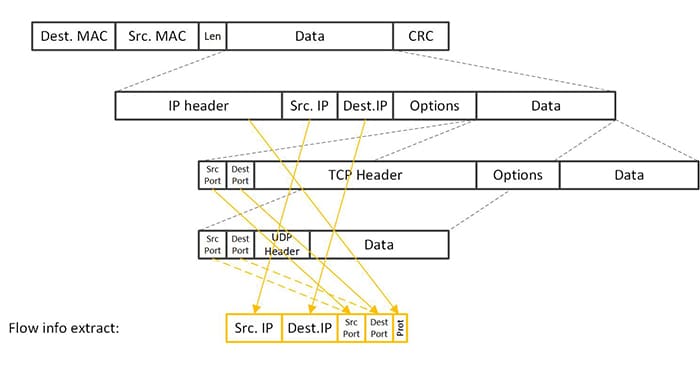
即使我们通过ip或者nmcli命令建立了许多可用IP,wrk测试时也只能使用访问目的IP时主机的默认IP地址作为源IP地址。由于源IP不可配置且数量只能为1,我们只能依赖于源端口的多样性来实现并发连接。然而,端口号是一个short类型的2字节变量,其取值范围有限,即使我们放宽操作系统的端口范围限制(在Linux中可通过sysctl调整net.ipv4.ip_local_port_range),端口的数量最多也只能达到6万多个,这远远不能满足百万级并发连接的需求。
为了解决这一问题,我们下面探索如何通过修改官方wrk源代码的方式,扩展wrk的功能,实现大规模并发测试。
wrk源码分析:放开默认源地址的限制
wrk并不是为测试C10M级别并发而编写的,但它的基因其实是支持的。我们首先要找到wrk限制源地址的代码,也就是wrk向服务器发起TCP连接的源代码段–src/wrk.c文件中的connect_socket函数:
1 | static int connect_socket(thread *thread, connection *c) { |
可见,该函数使用thread结构体中的addrinfo结构来确定目标服务器的地址信息,而源IP地址则是由系统自动选择的。如果需要自定义源地址,以便模拟来自特定IP地址的请求,可以在调用connect函数之前,使用bind函数将文件描述符(fd)绑定到指定的源地址。通过这种方式,可以控制从哪个本地IP地址和端口发起连接,从而满足特定的测试需求。
当然,做并发测试时并不需要指定源端口,所以将sin_port指定为0就可以继续使用操作系统分配的端口。
另外,究竟需要指定哪些IP作为源地址,还需要在wrk启动前做好准备,在main函数中获取这些地址后,再到connect_socket函数中使用,即可实现源地址的指定。这样,我们就绕过了高并发测试中TCP五元组的限制!
降低每连接消耗内存
要想使得wrk实现单机C10M级并发连接,还有1个问题需要克服:如何避免Out of memory问题?这个问题等价于,如何让每个测试连接使用尽量少的内存。
在深入探讨如何减少TCP连接所消耗的内存之前,我们必须首先理解TCP与HTTP协议在内存消耗方面的特点。wrk,作为一款专业的HTTP基准测试工具,其高效性能的实现基础在于对TCP流式消息的处理方式。wrk通过socket和系统API将TCP的流式消息缓存在内存中,仅通过指针引用来维护HTTP消息,从而显著降低了用户态进程中的内存占用。
然而,尽管wrk在用户态进程中对内存的管理做到了高效,但TCP和IP协议栈是由操作系统内核实现的,这意味着内核同样需要为每个TCP连接分配内存资源。内核的内存分配主要用于维护连接状态、缓冲区管理以及其它必要的网络操作,这些内存资源对于保持TCP连接的稳定性和性能至关重要。
为了减少每个连接的内存消耗,我们需要从两个层面进行考虑:
用户态进程中的内存优化:在wrk中,找到连接缓存、收发消息的代码,根据特定的测试场景减少其大小,或者采用更高效的数据结构来减少内存分配。
内核态的内存管理:对于操作系统内核中的TCP连接内存消耗,可以通过调整内核参数来优化内存使用,例如调整TCP缓冲区的大小、优化TCP的内存分配策略等。
关于内核态内存的调整,可以参见我的《高性能网络编程》系列文章,共有七篇,第7篇重点说了下内存调整:《高性能网络编程7–tcp连接的内存使用》
接下来我们重点来看wrk是如何为TCP连接分配内存的。
wrk源码分析:每个连接的内存分配
当我们通过-c指定并发连接数时,wrk.c文件中的parse_args函数会将参数保存到cfg->connections中:
1 | static struct config { |
在main函数启动wrk测试前,会根据-t指定的线程数,为每个测试线程计算好待分配的连接数:
1 | int main(int argc, char **argv) { |
然后在每个线程启动的thread_main函数中,预分配好每个连接能够使用的内存:
1 | void *thread_main(void *arg) { |
接下来是重点部分:每个连接消耗的内存预分配为sizeof(connection)大小,这到底是多大呢?我们继续看wrk.h文件中的connection结构体:
1 |
|
可以看到,对于发起测试的HTTP请求内容,wrk全局只保存了一份,由所有连接共享使用(参见char *request成员),而每个连接接收到的消息则各自保存在8KB大小的内存中(wrk需要分析HTTP响应结果)!也就是说,除了buf数组,connection结构体几乎不消耗多少内存(http_parser只维持了一些必要的状态)。
通过减小buf数组的大小(修改RECVBUF宏的值),我们可以降低每个连接所需的内存量。这种方法简单易行,因为它直接减少了每个连接在用户态进程中分配的内存空间。这不仅有助于减少总体的内存消耗,而且可以使得更多的连接能够在有限的内存资源下被建立,从而提升了并发连接的数量。
当然,这种方法需要仔细考虑测试场景的需求。如果缓冲区设置得过小,可能无法满足某些情况下的数据接收需求,从而影响测试的准确性。因此,合理地调整缓冲区大小需要在内存消耗和测试需求之间找到一个平衡点。
当然,你还可以设计更灵活的内存管理策略来进一步优化内存使用。例如,可以实施动态内存分配策略、共享缓冲区、延迟分配等,这些技术可以在保持测试准确性的同时,进一步提高内存的使用效率。
小结
通过对官方wrk源码的适当修改,我们能够有效地降低每个TCP连接的内存消耗,从而避免内存溢出问题,同时通过指定多个源地址扩展了TCP连接的上限。这些改动配合Linux系统内核的TCP连接内存优化,使得单机wrk测试能够达到C10M,即百万并发级别的性能测试,这为评估高性能系统在极端负载下的并发度提供了一种有效的手段。