12月7、8、9号三天在北京参加了BDTC大会,主题是人工智能与大数据,除了第一天的全员大会外,我参加了第二天上午的大数据云服务、下午的知识图谱、第三天的机器学习论坛。在此做一个回顾,也希望能为未参加大会的朋友们分享从我个人角度思考的心得。 禇晓文教授的《基于GPU的性能建模与分布式深度学习框架评价》是在GPU训练性能上讨论了benchmark分析方法。从CPU到GPU后,训练时间降低了一些,但能降得更多些吗?换成多块GPU显卡,可以再下降吗?应当采购什么样的显卡,性价比最好?这场分享回答了以上问题。
先来看一张图: 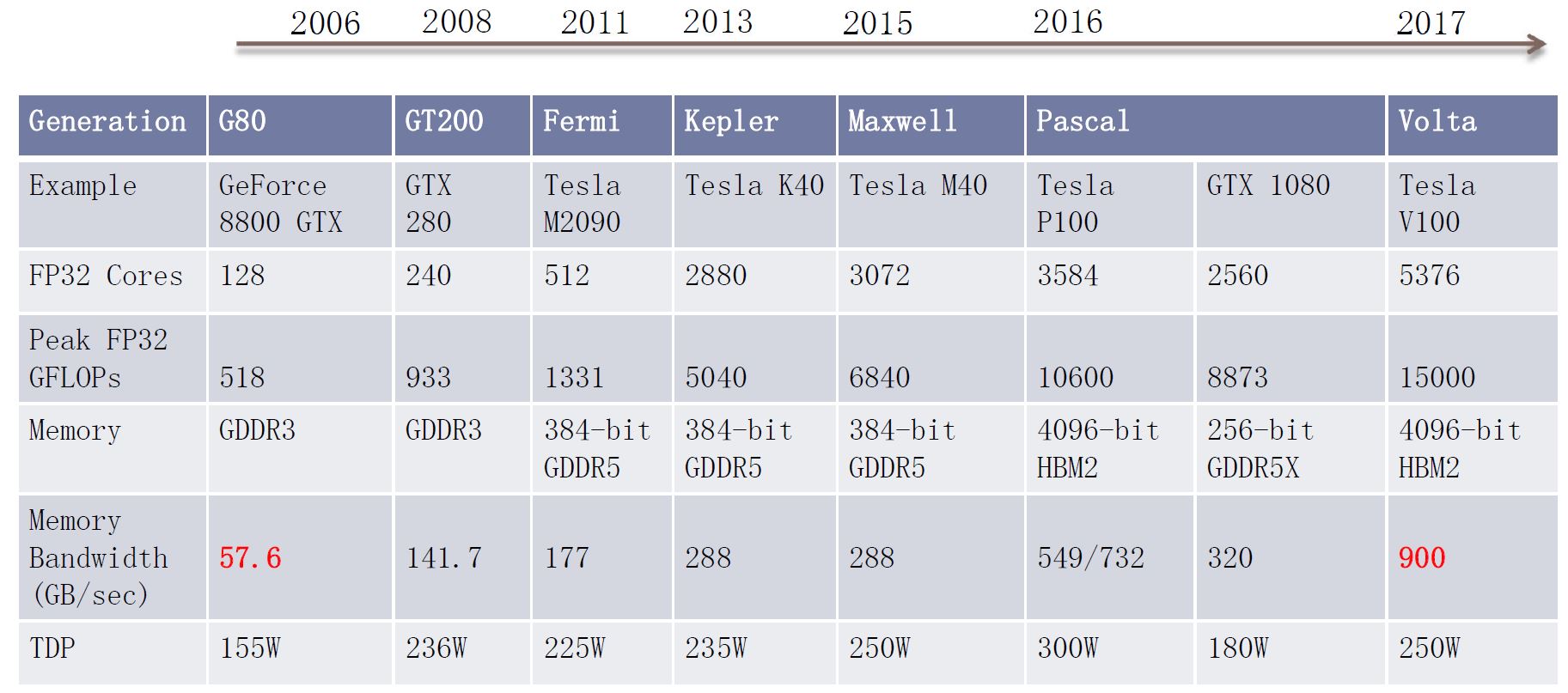 可见,显卡的计算单元ALU速度很快,从518到了15000 GFLOPS,翻了快30倍,然而显存带宽只翻了15倍,所以,显存带宽开始制约我们的训练效率。而且,一次矩阵计算至少需要两次读和一次写,对显存的操作本就更多。拿常用的gtx1080显卡来说,8.8TFLOPS和320GB/s的带宽吞吐能力,可见它们差不多有20多倍的速度差距。 所以我们通常采用多线程并行、编程控制共享显存、使用更快的显存等方法读写数据来减少速度差的影响,以使得GPU计算能力满载。
可见,显卡的计算单元ALU速度很快,从518到了15000 GFLOPS,翻了快30倍,然而显存带宽只翻了15倍,所以,显存带宽开始制约我们的训练效率。而且,一次矩阵计算至少需要两次读和一次写,对显存的操作本就更多。拿常用的gtx1080显卡来说,8.8TFLOPS和320GB/s的带宽吞吐能力,可见它们差不多有20多倍的速度差距。 所以我们通常采用多线程并行、编程控制共享显存、使用更快的显存等方法读写数据来减少速度差的影响,以使得GPU计算能力满载。
我们如何设计网络模型,以使得GPU可以满载呢?这里要引入一个指标OI(operational insensity),它表示计算量除以带宽FLOPS/BYTES。例如: 求两个向量的点积,每个向量含n个float变量,那么计算量是2n,读写字节数是2*n*4,故OI是1/4。 求矩阵与向量相乘,那么计算量是2n*n,字节数是(n*n+2*n)*4,故OI是1/2。 求两个n*n矩阵相乘,那么计算量是2*n*n*n,而字节数是(n*n*3)*4,故OI可能达到n/6。
而拿上面的GTX1080显卡举例,其OI达到8TFLOPS/320GB/s约等于28,所以至少需要OI达到28的运算才能把GPU跑满。 例如拿intel的E5345 cpu举例,其浮点运算能力是75GFLOPS,而内存带宽是10GB/s,那么其OI大概在7.5可以把CPU跑满,只有模型的OI超过7.5时,计算能力才会成为瓶颈,如下图所示: 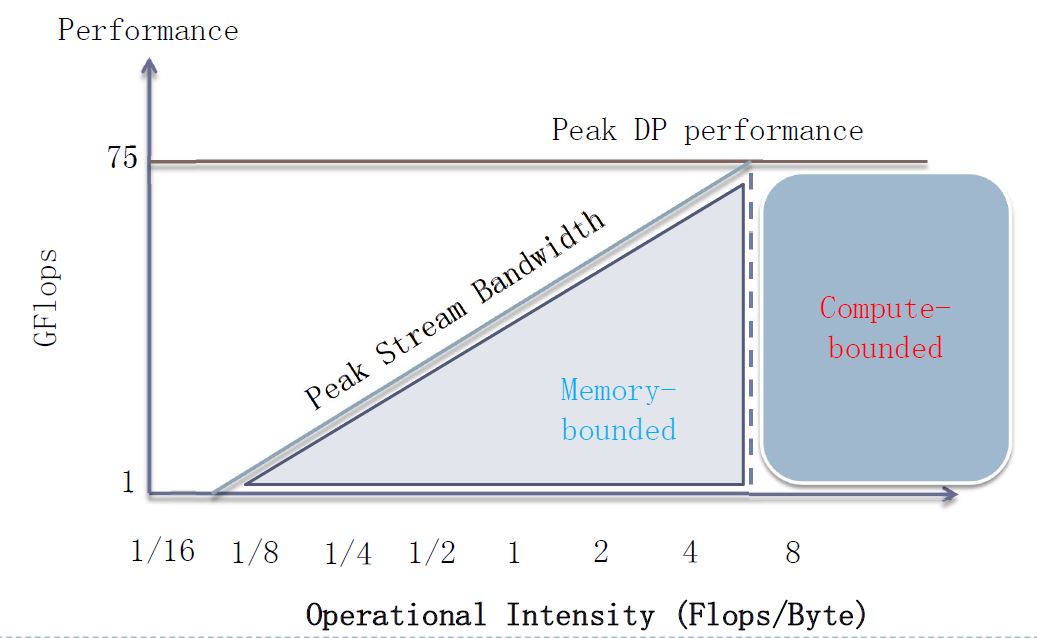
具体的模型不像上面提到的矩阵乘法那么简单,特别是现代网络的深度是很大的,下图是常见经典网络各层的计算消耗比例: 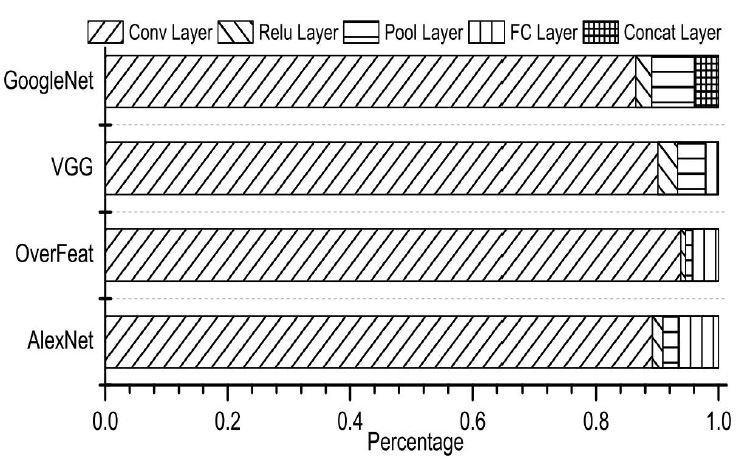 可见,卷积层是计算量最大的。而影响计算量的主要因素是卷积kernel size,所以一般kernel size都在3、5等较小的数字(都是奇数)。
可见,卷积层是计算量最大的。而影响计算量的主要因素是卷积kernel size,所以一般kernel size都在3、5等较小的数字(都是奇数)。
舒继教授的《大数据时代存储系统若干变化的思考》是一场关于深度学习训练过程的优化方法分享,关注点在前沿的工程领域,非常的酣畅淋漓!AI和大数据使得传统计算机课程都不再适用,我们心中的操作系统是这样的:CPU计算最快,它的寄存器是存储介质里在速度上最快的,其次是L1、L2等缓存,再次是内存,以上都是易丢失的存储介质,而能够落地的磁盘系统最慢(主要是机械硬盘)。所以操作系统、编译器做了大量优化,例如做IO处理时操作系统会有电梯优化算法,以加长一些IO的时延为代价,汇聚更多的IO批量读写以提高吞吐量。而现今来看,机械硬盘虽然单元存储价格最低,但时延高、吞吐量小、能耗高、可靠性低、随机读写性能差、发热量大,这必将被flash存储介质替换,如下图所示: 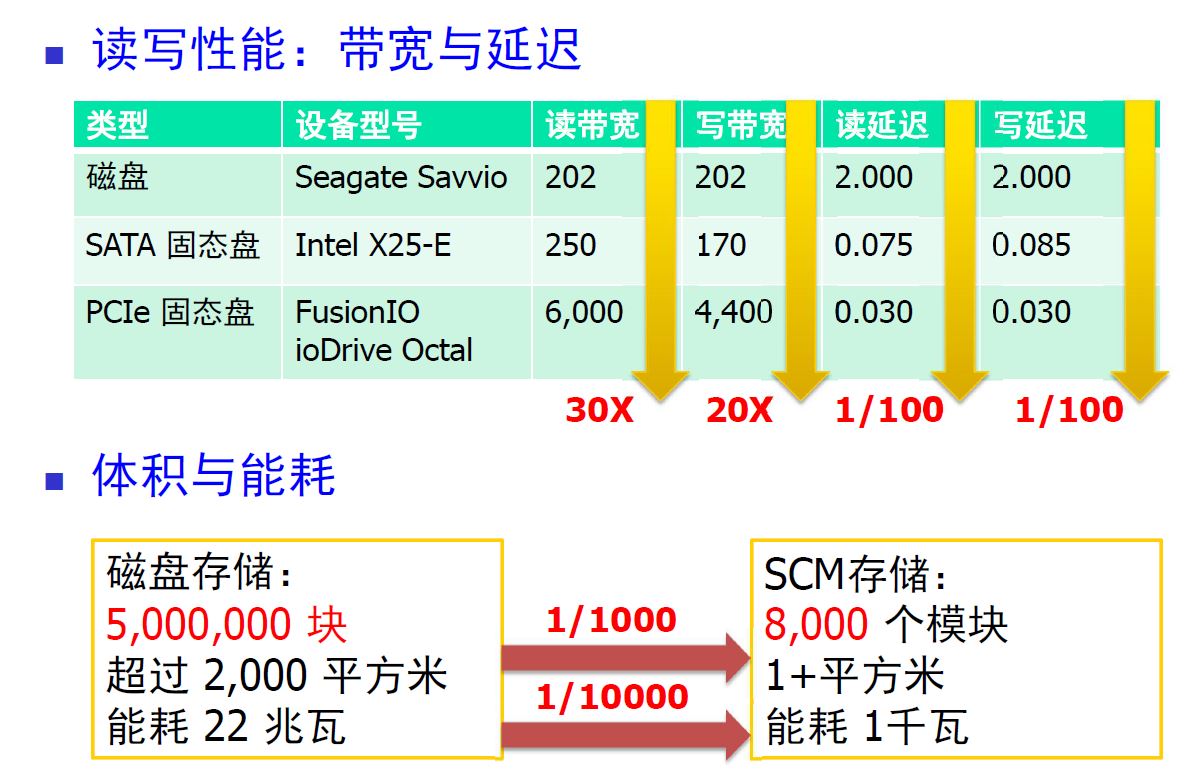
所以flash磁盘的大规模使用将对整个操作系统架构产生影响,例如原先的文件系统常假设外存为机械硬盘,所以有逻辑与物理地址映射管理、各种磁盘驱动程序、SATA接口等等。且各种非易失性内存技术的指标逐渐接近现在使用的DRAM内存,这会完全改变现有的系统架构。而从计算上讲,GPU由于专注于数值运算,其并行计算能力很高,从而大量的计算任务就跳过了CPU缓存、CPU寄存器,直接从GPU共享内存、缓存进入GPU计算单元中。因而,硬件的变化领先于低层软件系统,这意味着今后的底层系统会有较大的改变。
徐宗本院士的《模型驱动的深度学习》让我心有戚戚:学术界工作者和小公司的从业者们如何破除深度学习必然需要大数据作为训练基础的魔咒呢?大数据只有大公司才有,如此一来,最有活力的创业公司岂不是不要再玩什么深度学习、AI之类的东东了?破局点有两个:
- 第一,如果生产环境上并没有足够多的数据,除了下载些国外的开源标注数据外(国内标注数据真的很少),就像Alpha GO zero一样,没有大数据时大可以依据规则生成大数据,用生成的非真实大数据来训练模型,以解决冷启动时没有大数据的困境;
- 第二,如果把整个网络当成黑盒,每 一层都不知道其意义所在,那么自然只能靠堆砌大量的数据来拟合泛化。例如激活函数常见的relu等他们的表达能力都很差(为了减少计算量),所以需要大量的训练数据有效拟合,如果在优化网络时提高激活函数的表达能力,有目的的更换激活函数,则网络就有可能把规模降下来,从而不需要那么大量的训练样本。
当然,百度也给了一个方案,就是百度数据众包平台(百度两场分享都在介绍这个平台)。目前的深度学习基本都是监督学习,而监督学习需要的数据都是标注数据。百度有很强的整理清洗数据的基因,例如百度百科,基于人力进行数据标注。如此一来,百度就可以通过标注图片、语音、行业数据等来提供训练样本,提供了AI中的基础训练数据。可以感觉得到,百度相比其他巨头对AI行业布局的决心,可见“All in AI“不是说说而已!
长沙超算中心的彭绍亮带来的医疗AI实践的分享给我耳目一新的感觉。一直以来,我以为医疗AI只有IBM的watson,而国内只是还在信息化而已,还在采集脉搏血压心跳数据、连接患者、药厂、医生之中,如果算法能够开处方看病进入一线医疗,好像还非常遥远。而这场分享中,彭为我们描述了目前的实践已经到了可以开处方的地步,虽然只是辅助。而且由于国内信息保护很差,人口基数又大,因此中国比美国在医疗、人脸识别上有先天优势。所以,目前AI最热的三个领域有智能医疗就不足为奇了。
赛迪对《人工智能产业趋势和投融资分析》的分享帮助我们看到,现在北京还是AI投资最热的第一梯队,其领先于第二梯队上海、深圳、杭州之合。同时,中美的差距一如既往,但由于对信息隐私保护上中国还很差,以及中国巨大的网民基数,使得在红绿灯、人脸识别领域已经领先于美国了。非常看好中国AI产业的发展。
最后一定要吐槽,中国的大会一如既往的具有一个非常讨厌的特点:只要某一场演讲嘉宾是代表大企业的分享,那么几乎就变成广告宣讲会了,特别是产品总监或者非一线研发经理演讲时更是如此,全场都是在分享他们的产品特点。如果恰好你正在用这个产品时还稍好些(这概率真的极小),否则很浪费时间。仅有少数一线程序员会详细的说明如何实现、有哪些难点,遇到这种分享真是听众们的幸运了。当然,如果是学术界的讲师,那绝对都是业界良心,真的在分享知识和思路,可以开拓我们的视野,真心希望以后的大会组织者们注意下宣讲嘉宾的主题,不要把纯粹卖自家产品、夸自家企业的嘉宾放到这种技术大会的某场专题演讲中,哪怕提高些票价。