应百林哲笑含的邀请,于2018.6.9号至7.1号前往广州白云国际会议中心参加《CSDI Summit 中国软件研发管理行业技术峰会》。会上认识了很多互联网一线老师是最大的收获:  本次我分享的主题是《兼顾灵活与性能的nginx》:
本次我分享的主题是《兼顾灵活与性能的nginx》:

意外的惊喜是CSDI的讲师证书非常精美: 
最后附上本次演讲的PPT内容: 兼顾灵活与性能的nginx 以下为文字速录内容:
大家好,我是杭州市智链达数据有限公司的联合创始人和CTO,为什么又要介绍一下?因为我们公司是一个互联网服务企业,但是我们面向的客户是建筑企业,所以在座的各位都不是我的潜在客户,所以接下来不会有任何介绍关于我们产品的推广和介绍:-)。从我的这个分享的标题中可以看到,这里其实有两个关键词,一个是性能,一个是灵活,我们接下来讨论这两点中nginx是怎么做到的。当前nginx已经是所有的互联网企业的一个标配底层组件,所以能分享这样一个大众化的广为使用的工具,我个人感到很荣幸。不管是小流量还是大流量场景使用了nginx后都可以有一个立竿见影的效果。
那么本来的话nginx介绍这部分可以没有,但是我相信在座的各位应该在生产环境中时实际操作过nginx的同学应该不是很多吧?能不能请在生产环境中直接使用过nginx,或者你带的团队负责nginx的同学,能不能举一下手?我看一下还是有一半以上的同学没有操作过nginx的,所以我会用五分钟的时间先做个简单的介绍。
首先我们肯定是先看它的使用场景,那么场景的话呢先从这个最右边的这个静态资源来看,我们现在不管是开发一个web页面或者是开发一个APP webview,都会去拉取大量的CSS、JS、小图片等资源,这些资源的空间占用量其实很大,也很难放在内存中,所以只能放在磁盘上。nginx非常擅长把磁盘中的内容以http协议的方式返回给客户端,所以这是nginx第一个场景。第二个场景中,如果我们的应用服务是用python写的,可能也就几百QPS,JAVA写的服务可能有上千QPS,如果是GOLANG写的可能有上万QPS,但是nginx拥有上百万QPS的系统能力,所以如果我们需要尽量提高我们的这个系统容量,那么需要把很多的应用服务组成一个集群来对用户提供服务,在早期的时候,我们可能会用DNS等手段做负载均衡,而现在呢都是采用nginx做反向代理,因为它卓越的单机性能很适合该场景。那么在反向代理使用场景中就会有另外一个问题,负载均衡,我们经常会需要扩容,宕机容灾时这个负载均衡可以发挥很好的作用。那么有了反向代理后又会引出另外一个问题就是缓存。
因为其实在互联网行业中,只要我们想提升用户的体验,基本上都是在缓存上下功夫,而缓存基本上你是放在离用户越近的地方效果越好。比如说你放在手机APP的存储上,或者放在浏览器的storage里,这样的用户体验最好!或者说再差一点到网络中了,那么放在cdn效果也是很好,但如果请求到了我们企业内网中,这个时候,往往离用户最近效果最好,比如说像mysql数据库它虽然专注于只做一件事,以致于他的这个缓存做的是非常厉害,但是他的能力再强也没有用,因为数据库前面会有一个业务应用服务,应用服务强调的是快速迭代,它强调的是对程序员友好以提升开发效率,所以呢你想它性能好是不可能的。所以这个时候呢我们在这个nginx上做缓存,因为反向代理协议就很简单,做缓存也很方便,我们最后也可以拿到好的结果。
第三个场景呢就是中间这个广场。有一些高频的接口调用,比如说像用户鉴权,还有像前天有一位阿里巴巴国际部的老师说他们的流量导流等应用,这些东西都需要这个nginx要发挥自己的特长,然后不要跟慢吞吞的应用服务扯上关系。就像我刚刚说的,其实数据库例如mysql他的能力是很强的,那么如果这些业务可以直接在nginx上实现,那么其实我们就可以提供一个API。那么API服务实现上有几个难点,第一个呢以前的nginx往往是通过每个第三方模块自行定义它自己独特的配置格式,以此实现复杂的业务功能,但这种模式是会有很多问题,因为你是独特的不是通用的,而且且学习成本很高,扩展性也不好。所以呢以通用编程语言实现是一个好思路,官方还搞了一个javascript版本,而openresty搞了一个lua版本,那么因为引入了编程语言,那么你可以很方便的调用工具SDK,所以做API服务就有了可行性,这是最主要的应用场景。
OK那么再看一下nginx的进程架构,我相信在坐的各位都知道nginx的master/worker进程模型。但是我不知道大家有没有想到为什么是一个多进程的架构?可以横向对比一下,比如说nodejs,比如说redis,他们都有一个明显的问题:就是没有办法使用多核。那么nginx呢,因为他在定义核心目标时,他想做的事就是在我们企业内网最外层,获取这台服务器的极限能力以实现上述功能,所以nginx希望能够有效的耗尽cpu、内存等资源。那么master进程它其实非常轻量级,他只是去监控,只是去管理,虽然master也提供了钩子方法供第三方模块介入,但其实像很多第三方模块并不会在master里面做文章,因为只要你有业务在master里就引入了不确定性,master是不能挂,挂了以后你没有办法管理实际工作的worker进程。如果我们做缓存的时候,其实又多了两个进程cache manager和cache loader,这两个进程也是不处理实际请求的。
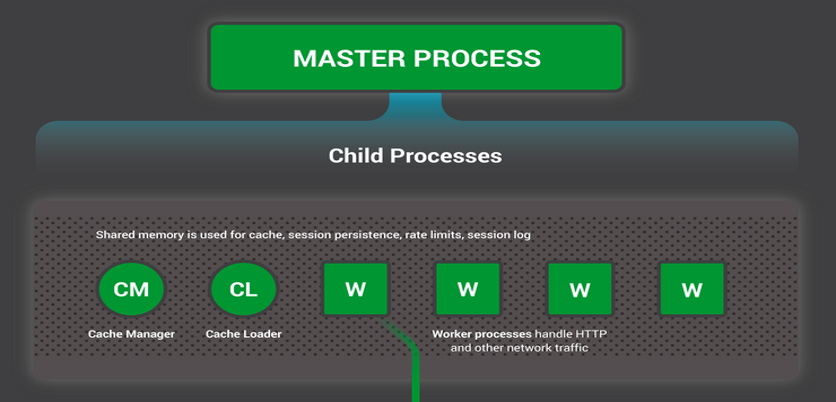
再看一下编译方式。nginx通常是采用把官方的源代码和这个第三方模块的源码放在一起编译出一个二进制可执行文件,那怎么编译?官方他会提供一个叫bash脚本叫configure,而Tengine或者openresty也会提供自己的configure脚本,它负责把这些源代码以有序的方式整合在一起(下面会说到)。那么编译出来这个二进制文件之后呢我们就可以运行了。近期的版本nginx向大家提供了动态模块的功能,就像windows操作系统中的dll,或者linux操作系统中的so,它们又提供了一层封装,降低了耦合度。就像图中所示,这时候就会把这个动态库打开,把其代码加载至nginx的进程地址空间中,那么有了这个动态模块好处在哪里?如果说我只修改了一个模块,并未对其他模块发生变动,那么就不用重新编译出新的可执行文件了,我只要去换一下这个动态库就可以。
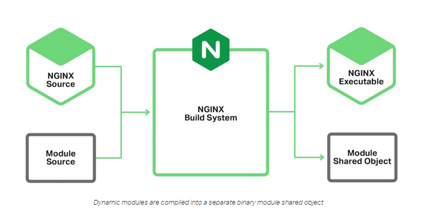
灰度发布可能大家都比较清楚,这是nginx的基本功能了,我们简单过一下。比如说上面这张图,master进程上拉起了四个绿色的worker进程,这四个worker进程用的是老配置文件里的配置,然后呢我们修改了nginx.conf配置文件,调用了-s reload命令后,master进程会起四个黄色的worker进程,这四个黄色的worker进程使用了新的配置文件里的内容。如果我们自己去写一个应用程序实现配置修改时,不知道大家会怎么写?那我可能会想,把应用进程kill掉,再重新拉起读取配置不就完了吗?那是nginx不能这么做,因为它上面真的跑了几十万个tcp连接,所以如果他被kill掉,实际上几十万的客户端都会收到RST复位包,体验是非常差的。所以nginx要采用这么一个复杂的形式,就是绿色的worker进程还在处理老的连接与请求,而黄色的worker进程就只处理新建立的连接与请求,等到绿色的老worker进程处理完老连接上的请求后,我们再停掉worker进程就没有问题了。但是说起来很简单,其实还是有许多问题要处理,比如说如果是HTTP这样的请求那还比较好,即使是keepalive连接也OK,但如果是websocket协议或者其他TCP协议怎么办?nginx不解析协议内容,不知道什么时候可以准确的判断处理完一个请求,这样粗暴的方式就可能直接断用户连接。worker_shutdown_timeout这个配置就是做这个事的。
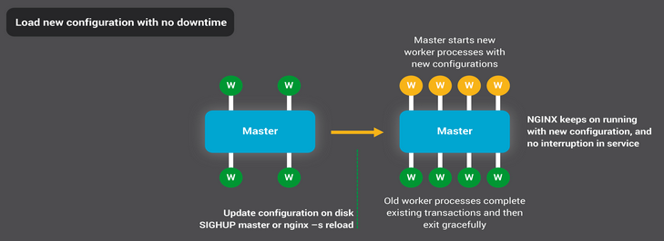
那我们现在进入第二部分谈谈nginx的模块化。模块化决定了nginx的能力,比如说TCP这个协议,它是上世纪70年代就发明了,我们中间可能有各种各样的改进,比如说拥塞控制等等,但是到了现在还是非常好用。其实nginx也一样,我们掌握了它的模块化思想,就理解了它的底层能力。nginx的模块我不知道如果让你去设计,你会怎么思考?看下这个图,首先它会有核心模块core,这下面的四个模块是框架与工具模块,比如说这个errlog是记录错误日志的。这上面这四个核心模块,每一个都定义了一类新模块。这个就比较关键,那么像这个mail等模块并不重要,我们重点还是看http模块。所有的http模块他们其实就构成了一张数组列表,这个列表里面的第一个元素也是第一个http模块都有个关键字_core_,包括mail、stream模块都是一样的。那么每类模块列表里的第一个core模块存在的意义在哪里呢?它们负责处理本类模块里的共性规则。第一个共性的东西就是协议,比如http协议,一定先是一个请求,请求中先收到url及版本号等,再收到header包头,那发送响应的时候也是先发送line再发送header再发送body。那么我就可以把这个逻辑抽象出来。接下来我们会重点看逻辑是如何抽象出来的。然后呢可能还有一些公共的工具,也可以由第一个core模块来做。
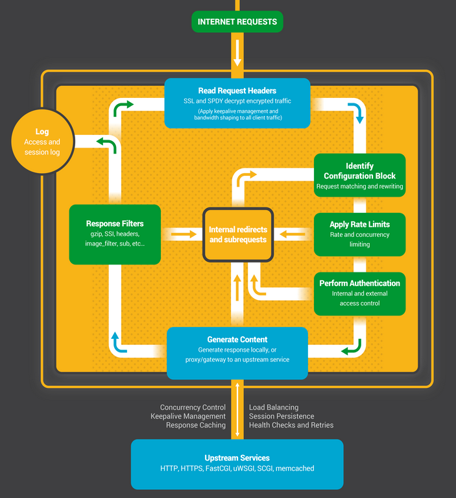
那么http response的响应过滤也有许多共性的抽像,因为我们返回http协议内容的时候可以做很多事情,比如说做压缩、生成缩略图,这个时候呢其实就是在body和header上做文章,所以nginx又引申出来一个概念叫响应过滤模块。我们现在看这张图,先看左边这边传播非常广泛的官网图片,从这上面到达一个internet request,首先读完它的header头部,读完以后呢,这时候判断我的安全模块是否应生效,包括用location正则表达式匹配url决定用哪些配置,我可能会做一些限速。生成response响应内容就是generate content,可能我读本地的磁盘文件实现,也可能我跟上游的一个服务交互获取其内容等等,这个事情做完以后,我拿到了http response,此时开始对header和body进行过滤模块的处理,做完以后呢记录access日志,这个日志用来做监控运维,最后把response返回给用户。
再来看HTTP模块抽象出的11个阶段。比如说现在有一个realip模块,如果需要你去实现这个模块去获取用户的真实IP,我不知道你会把该模块放在哪个阶段?因为实际TCP连接它实际上是个四元组,当nginx与用户中间有反向代理的话,其实你从连接的source ip获取到的地址不是用户的,怎么办呢?除了复杂的proxy protocol等方案外,应用层的HTTP协议很有办法,它可以通过把用户的原始ip在request http header中带来。所以如果我们去实现这样的一个http模块,可以搞一个nginx变量去存取header头部的ip值,这个http模块到底放在11个阶段的哪个阶段就是个问题,因为前面的这些模块都有可能去改http header的,只要其他http模块有能力去改,realip模块获取到的ip可能就有问题。所以,在post_read模块,顾名思义,就是刚读取完http request header,此时去处理最合适。再到下面是rewrite相关的三个阶段,一个叫find config在其中。rewrite模块是官方模块处理的。
接下来看访问控制相关的3个阶段。比如说输入用户名和密码自然在access阶段,但是如果说你要做流控,你肯定要在他之前,否则的话这个流控可能就失效了,请求流量有机会打到access阶段这里。因此流控必须在pre_access阶段。OK现在看一下这个http模块的工作流程,我做了一个动画,怎么看呢?先从左边看这个绿框,这个绿框表示master进程在启动,它首先读取nginx.conf配置文件,这里会依次从上至下读取这个ascii文件,当它发现events {}配置时,自动将大括号里的内容交给event事件模块解析,而发现http{}时就交给http模块处理,stream{}里的内容自然交给stream模块处理。对于http模块而言,有些http模块会根据配置项决定是否将其钩子函数添加至处理流程中。http core模块会负责将所有的location建立为一颗树以加快访问速度,最后还要将listen后跟着的端口加入容器中,接着读完配置文件就开始listen打开监听端口,再fork出子进程。子进程worker会继承父进程已经打开的句柄,自然也包含端口。master进程接下来就只监控worker子进程,以及等待接收信号命令好了。而worker进程则只处理事件以及接收master发来的信号命令。当worker进程收到SYN包,开始建立连接,请求处理流程就开始了。首先用HTTP状态机确保接收到完整的HTTP的header头部,再依次调用刚刚介绍过的11个阶段的HTTP模块去处理请求,在content阶段处理完后生成了http resposne,再调用各http filter模块加工response,最后发送出去。
再看看怎么找到location下的配置去处理请求的。tcp连接是四元组,所以可以根据lister时的ip address去获取连接,寻找由哪些server{}去建立连接,就像图中的最左边,其配置如下所示:
1 | server { |
接着,我们接收完http request header后,可以从HOST头部获取到域名,而这可以匹配server_name配置后的虚拟主机域名列表,这样就唯一确定了一个server{}配置块。从URL中还可以再次匹配location后的正则表达式,这样我们就找到了具体的location配置。
再看这张图,我们谈谈11个阶段间http模块间的配合。这里仅以官方模块举例。当一个请求读完http header后,我们先进入preaccess阶段,这一阶段里有两个模块:limit_conn和limit_req模块。前前限连接,后者限请求。可见,前后顺序乱不得,否则就导致limit_conn无法正常生效了。当limit_conn模块决定请求不受限制后,它会返回NGX_OK给钩子函数,这样进入当前preaccess阶段的下一个模块limit_req模块继续处理。而limit_req模块也认为不受限制,可以继续处理,因为当前preaccess阶段没有其他模块了,故进入下一阶段access阶段继续处理。而在access阶段中,若第一个模块auth_basic认为无须进入下一个access模块处理,那么它可以返回NGX_AGAIN给钩子函数的调用者,这样access阶段其后的模块是得不到执行的。可见http模块还是很灵活的。当content阶段生成内容后,首先由header filter模块处理。为什么呢?因为http是流式协议,先返回header,再返回body。比如我需要做压缩,那么就需要先在header中添加content-encoding头部,再压缩body。这里需要注意的是,这些模块间也有顺序要求!比如现有一张图片,你只能先做缩略做再压缩,如果反过来,压缩后是没办法做缩略图的。所以这个顺序也是由configure这个脚本决定的,大家可以看源码时看到里面的注释明确的写着不能改order顺序。 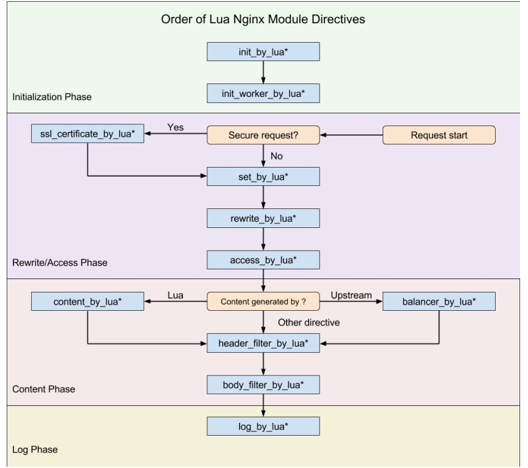
这张图是openresty官方的图。用好openresty的关键是,搞清楚指令与sdk。其中sdk比较简单,就是形如ngx.xxx这样的函数,可以在lua代码中调用。它实际上就是lua与C语言的交互,通过先在nginx模块中提供相应的函数,再封装给lua作为lua函数即可,目前主要在用ffi方式,最新的openresty都在用ffi方式重构。而指令就是nginx配置,它会决定其中{}大括号内的代码在什么时候执行。这张图中,有初始nginx启动阶段、有rewrite/access阶段、有content阶段以及log阶段。这与我们之前的所说的11个阶段有什么关系呢? 我们来看这张图,有点复杂,最上面的绿框是nginx启动过程,其中黑色的框是master进程,而紫色的框是worker进程,中间的红点是钩子函数。中间的紫色框是worker进程在处理请求。最下面的绿色框是nginx在退出。可以看到,当nginx启动在,通过在配置文件中各第三方模块可以介入,在init_module回调函数实现东西也可以介入nginx的启动。当派生出worker子进程后,仍然可以通过回调init_master、init_process等回调方法介入启动过程。而实际处理请求时,先可以通过8个http阶段介入与请求的处理,在content阶段还可以使用排他性的r->content_handler(用于反向代理)来生成响应内容。在生成响应内容时,还可以通过init_upstream钩子函数决定选择哪一台上游服务器。生成响应内容后,通过filter过滤模块也可以介入请求的处理,最后在access log阶段也可以介入请求的处理。在nginx退出时仍然可以介入处理。 而openresty的指令就是像图中这么介入处理的。例如,rewrite_by_lua实际是在post_read阶段介入处理的,因为就像上面说过的,rewrite阶段都是官方模块在处理,所以openresty实际是在postread阶段,所以这个指令是相当靠前的。而balance_by_lua实际是在init_upstream钩子里介入的。
最后我们看一下nginx变量。有一类模块会生成新的nginx变量,它们通过处理http请求时定义的取值方法,生成了变量名对应的变量值,并以$符号或者lua中的ngx.var等方式提供给使用变量的模块。这些模块既包含C模块,也包括lua模块。C模块更关注高效,往往提供变量的模块都是C模块,而lua模块关注业务。所以,这两类语言最好的解耦方法就是使用变量。 最后我们看看第三部分nginx性能的优化。我们希望nginx可以把一台服务器的性能压榨到极致,主要从5个方面入手。首先是不能有长时占有CPU的代码段。因为nginx是事件驱动的、非阻塞的、异步架构代码,就像图中所示,nginx把本来操作系统应该做的事:切换不同的请求处理,改为在nginx进程内部处理了。怎么讲呢?传统的进程是同一时间只处理一个请求,所有处理请求的方法都是阻塞的,所以在处理完一个请求前不会处理下一个请求。因此,当大量并发请求存在时,意味着大量运行中的进程或者线程。操作系统希望最大化吞吐量,它就会切换不同的进程到CPU上执行,当一个进程因为阻塞请求导致的系统调用不满足时,例如读取磁盘转头磁头,就会被切换到内存中等待下次执行。而nginx采用的事件驱动,则是把这一过程放在nginx的用户态代码内了,首先用非阻塞系统调用检测到条件不满足,如果执行会导致操作系统执行进程间切换时,就会把该请求切到内存中等待下次执行,而nginx会选择条件满足的请求继续执行。因此,如果处理一个请求时消耗了大量的CPU时间,就会导致其他请求长时间得不到处理,以至于大量超时,形成恶性循环。所以,遇到某些第三方模块会大量消耗CPU时务必谨慎使用,真有这样的场景也不应当在nginx中做,可以用nginx反向代理到多线程应用中处理。因为操作系统会为每个进程分配5ms-800ms的时间片,它也会区分IO型或者CPU型进程,而上述进程是明显的CPU型进程,上下文切换不会很频繁。 第二个优化点就是减少上下文切换。在这页PPT中我们提到一个工具叫pidstat,它可以清晰的看到主动切换与被动切换。何谓主动切换呢?就是执行了某些阻塞式系统调用,当条件不满足时内核就会把进程切换出去,叫做cswch/s。而操作系统微观上串行宏观上并行实现的多任务,是使用抢占式内核实现的,它为每个进程分配时间片,时间片耗尽必须切出,这就叫nvswch/s。我们通过增加进程的静态优先级来增大时间片的大小。静态优先级分为40级,默认进程是0级,最大是-19,我们可以在nginx.conf里修改静态优先级。另外,还可以通过把worker进程绑定CPU,减少在多核服务器上的进程间切换代价。对于主动切换,则需要减少使用类似nginx模块的场景。有时这很难避免,例如读取静态文件,当频繁读取的内容打破内存缓存时,使用nio或者sendfile也没有用,仍然退化为阻塞式调用,此时用threadpool线程池就很有意义了,官方有个博客上提到此种场景下线程池有9倍的性能提升。当然,目前线程池只能用于读取静态资源。 第三个优化是减少内存的使用。很多并发的连接是不活跃的,但它们还是会在内核态、用户态占有大量的内存,而总内存其实很有限,所以我们的内存大小及各种内存相关配置影响了我们的并发量。先从连接谈起,在Nginx进程内为每个连接会分配一个ngx_connection_t结构体,每个ngx_connection_t各分配一个ngx_event_t结构体用作读、写事件,在64位操作系统下以上结构体每个连接(无论是TCP还是UDP)消耗的内存是232+96*2字节。在操作系统内核中,为了处理复杂的TCP协议,必须分配读、写缓冲用于进程的读写、滑动窗口、拥塞窗口等相关的协议收发,而linux为了高效使用内存,设立了普通模式和压力模式,即内存宽裕情况下为每个连接多分配一些缓存以提高吞吐量,在压力模式下则每个连接少分配一些缓存以提高并发连接数,这是通过tcp_moderate_rcvbuf开关控制的,而调整幅度可通过tcp_adv_win_scale控制,调整区间在读写缓存上设置。Nginx中含有大量内存池,形如*_pool_size都是在控制初始内存分配,即必须分配出去的内存。还有一类分配如8 4K这样的多块不连续内存,比如对于large header或者gzip buffer等,它们使用ngx_buffers_t结构体存储。共享内存是用于跨worker进程通讯的,而openresty里的share_dict就是通过共享内存实现的,当然使用共享内存通常要用slab伙伴系统管理内存块,再用rbtree红黑树或者链表等数据结构管理实际的逻辑。Nginx中还会用到大量的hash表,比如存储server_names等,这里会定义桶大小和桶个数。 第四个是优化网络。我们先从TCP层面看,无非是读、写消息、建立与关闭连接等功能。如果是读消息,我们需要关注tcp_rmem设置缓存区的大小,需要关注初始拥塞窗口rwnd的大小以提升网络可以快速达到最优值。在nginx上还有许多控制读取到固定消息的超时时间,在读取上游服务发来的响应时还可以通过limit_rate限流。在发送消息时,同样可以设置tcp_wmem设置缓存区大小,通过iptables命令对cwnd来提升初始窗口,nodelay和nopush都是为了提升吞吐量的算法,当然它们的副产品就是牺牲了及时性增大了latency。总体来说对于大流量场景应该打开它们。当然nopush只对sendfile有效。当发送响应给客户端时,也可以通过limit_rate进行流控。作为服务器建立连接时,Tcp Fast Open技术可以在SYN包里就携带请求,这减少了一次RTT,但有可能带来反复收到相同包的情况,一般不打开;使用Defered可以减少nginx对某连接的唤醒次数,提升CPU使用效率;reuseport可以提高负载均衡效果,使多worker进程更好的协同工作;backlog可以增大半连接与全连接队列,特别是新连接很多而Nginx worker非常繁忙时。关闭连接最复杂,特别是nginx主动关连接时,fin_wait_1状态下linger可以控制关连接的时机以减少RST包的发送;tcp_orphan_retries控制发送次数。fin_wait_2状态下可通过tcp_fin_timeout控制超时时间。在time_wait状态下通常会打开tcp_tw_reuse提升端口的利用率,但tcp_tw_recycle会使得time_wait状态近乎消失,这会带来端口复用时被丢包补发的FIN包关闭连接。 最后是减少IO调用。这只对读取本地的静态资源有效,例如打开sendfile采用了零拷贝技术就减少了内存拷贝次数以及进程间上下文切换次数。
最后对今天的演讲做个总结。我前阵子听梁宁的30堂产品课,上面说到看待产品或者人都是从5个层面,我觉得很适用于nginx。首先从表面层。例如相亲时先对异性的长相、谈吐、衣着,而看nginx则是看它的配置文件格式、access.log日志格式、进程启动方式等。第二层是角色层,例如与一个同事沟通,那么他是HR或者是前端工程师,都会影响他的谈吐以及沟通方式。而nginx的角色层就是最开始提到的静态资源服务、反向代理、API服务器,这影响它的表现层。第三层是资源层,对人则是人脉资源、精神资源、知识结构等,而对nginx则是它的大量的第三方模块、社区等。第四则是能力圈,对人就是一个人的能力大小,对nginx就是上文提到的nginx的核心架构、模块化、设计思路、算法、容器等。第五层是最内核的存在感,对人则是什么状态能让人满足,对nginx则是它的设计意义,就是我们前面提到的把一台服务器的硬件能力使用到极限以提供强大的web服务能力。这里底层总是在影响着上层,所以当我们掌握了nginx的底层,无论上层怎么变都很容易理解。
OK最后我在这里做个广告,智链达是一家杭州的创业公司,是希望助力一个行业实现转型升级的互联网服务公司,目前各种岗位都在招聘,我们其实面向的是一个蓝海行业,希望各位有兴趣的同学考虑加入。行,那我今天的介绍到这。